Will be migrated to blk_basis
Background of introducing blk-mq
Design of blk-mq
Source code of blk-mq
+----+ +----+ +----+ +----+
|cpu0| |cpu1| |cpu2| |cpu3|
+----+ +----+ +----+ +----+
||
\/
+-+-+-+ +-+-+-+ +-+-+-+
default | | | | read | | | | poll | | | |
+-+-+-+ +-+-+-+ +-+-+-+
|| || ||
\/ \/ \/
+-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
|D| |D| |R| |R| |R| |R| |P| |P| |P| |P|
+-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
.----->-----.
/ \
\ Round-Robin /
'-----<-----'
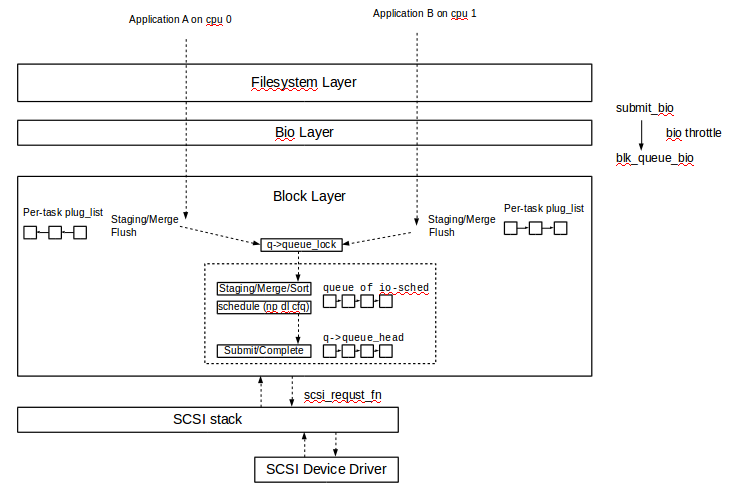
The scalability under multiple cores (even with NUMA) and high IOPS NAND-flash SSD is the bottleneck.
Request queue lock which synchronizes the exclusive resource of one request_queue is really a devil. It will cause high contention and continuously cache-line bounce on muliple-cores system, even worse on NUMA.
Both of them will harm the performance of block layer on high IOPS SSDs.
(It seems to be acceptable on slow storage device such as HHD)
Nearly all the operations in block layer need this request queue lock.
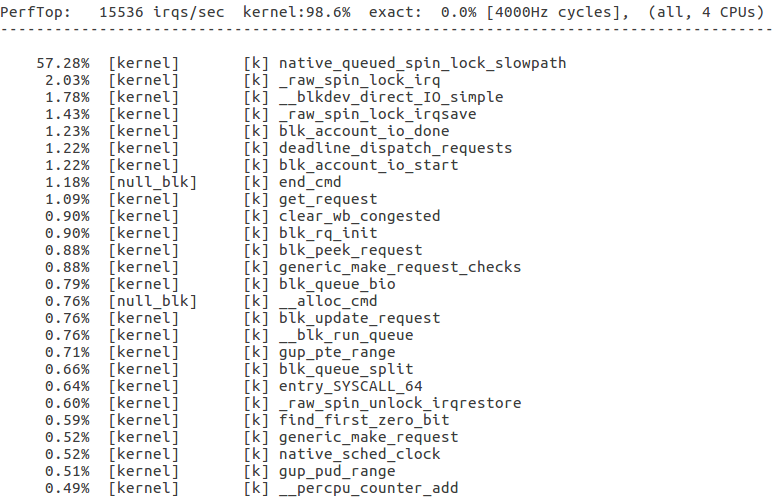
The perf top result on blk-null.
sudo modprobe null_blk queue_mode=2 completion_nsec=0 irqmode=0
Data on an HDD is stored in concentric tracks on platters (the recording media). An actuator arm with a read/write head moves on top of the platter to perform the actual read or write operation, moving from track to track. The moving of the actuator arm is costly. A lot of heuristics and optimizations in block layer serve for reducing actuator arm movements. They are good for HDD, but maybe not for SSD.
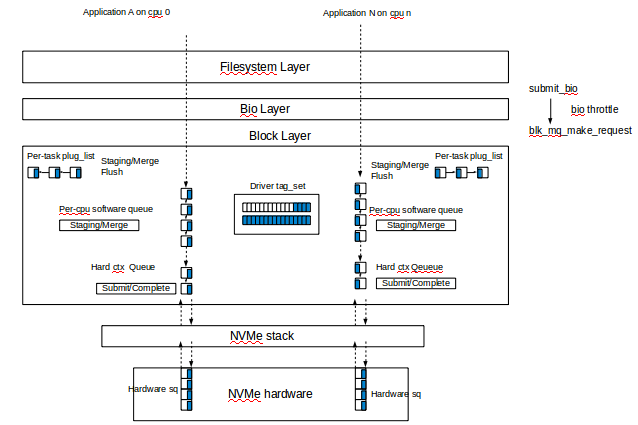
block legacy layer is not for _high_speed_ SSDs
Oct 24 2013 blk-mq: new multi-queue block IO queueing mechanism 3.12.0-rc5 320ae51 Jan 17 2014 scsi: add support for a blk-mq based I/O path 3.16.0-rc5 d285203 Jan 17 2017 blk-mq-sched: add framework for MQ capable IO schedulers 4.10.0-rc3 bd166ef Jun 16 2017 scsi: default to scsi-mq 4.12.0-rc5 5c279bd Aug 13 2017 Revert "scsi: default to scsi-mq" 4.13 cbe7dfaThe performance regression which cause the revert and its fix:
The performance regression "In Red Hat internal storage test wrt. blk-mq scheduler, we found that I/O performance is much bad with mq-deadline, especially about sequential I/O on some multi-queue SCSI devcies(lpfc, qla2xxx, SRP...) Turns out one big issue causes the performance regression: requests are still dequeued from sw queue/scheduler queue even when ldd's queue is busy, so I/O merge becomes quite difficult to make, then sequential IO performance degrades a lot. This issue becomes one of mains reasons for reverting default SCSI_MQ in V4.13."https://lkml.org/lkml/2017/10/14/65
Device command tagging was first introduced with hardware supporting native command queuing. A tag
is an integer value that uniquely identifies the position of the block IO in the driver submission queue, so when completed
the tag is passed back from the device indicating which IO has been completed. This eliminates the need to perform a
linear search of the in-flight window to determine which IO has completed.
On the other hand, these tags could indicate the capacity of the hardware submit queue.
The nvme exploit the tags in blk-mq fully.
nvme_queue_rq()
-> nvme_setup_cmd()
-> cmd->common.command_id = req->tag;
nvme_irq()
-> nvme_proccess_cq()
-> nvme_handle_cqe()
-> blk_mq_tag_to_rq()
-> nvme_end_request() // cqe->command_id
-> blk_mq_complete_request()
There is two kinds of tags in blk-mq, sched-tags and driver-tags.
The driver tags is the tag we said above. The sched tags is associated with the io scheduler.
In the comment of the commit which add the MQ capable IO scheduler framework (bd166ef), Jens Axboe said:
We split driver and scheduler tags, so we can run the scheduling independently of device queue depth.
In the blk-mq code:
blk_mq_init_sched()
>>>>
/*
* Default to double of smaller one between hw queue_depth and 128,
* since we don't split into sync/async like the old code did.
* Additionally, this is a per-hw queue depth.
*/
q->nr_requests = 2 * min_t(unsigned int, q->tag_set->queue_depth,
BLKDEV_MAX_RQ); //BLKDEV_MAX_RQ 128
queue_for_each_hw_ctx(q, hctx, i) {
ret = blk_mq_sched_alloc_tags(q, hctx, i);
if (ret)
goto err;
}
>>>>
The max nr_tags of sched is 256. For the qla2xxx of which queue depth is 4096, is it too small ?.
Actually no. The reqs in io sched's queue will always be dispatched to hctx->dispatch queue and hardware dispatch queue. If there are too many reqs residual in io sched queue, there must be some issues in hardware.
These two tags both have its own static request arrary.
blk_mq_alloc_tag_set()
-> blk_mq_alloc_rq_maps() // the actual depth may be lower than the set->queue_depth
-> __blk_mq_alloc_rq_maps()
-> __blk_mq_alloc_rq_map() //per-hctx-idx set->queue_depth
OR
blk_mq_init_sched()
-> blk_mq_sched_alloc_tags() // per-hctx q->nr_requests
-> blk_mq_alloc_rq_map() // alloc tags->rqs and tags->static_rqs arrary
-> blk_mq_alloc_rqs() // alloc pages to carry the (request + driver payload)
-> blk_mq_ops->init_request()
blk_mq_get_request()
-> blk_mq_rq_ctx_init()
-> blk_mq_tags_from_data() // hctx->tags or sched_tags
-> rq = tags->static_rqs[tag] // when w/o io scheduler
when w/ ioscheduler, the reverse mapping is done in blk_mq_get_driver_tag()
The request instance could come from driver tags or sched tags. But no
matter w/ or w/o io scheduler, the request must be saved in hctx->tags->rq[] as
a reverse mapping from tag to request.
request_queue->queue_hw_ctx[] -> sched_tags -> static_rqs[]
| /
V ___ ___ __/____ ___
tags | | | | | | w/ scheduler
| |___|___|___|___|___| <------------+
| /\ \
| / \ \
/ _________/ \___________ \
/ | request + driver payload | \
------------------------------------------------ \
/ |
| maybe shared (Multiple LUs SCSI HBA, or Multiple ns NVMe) |
V |
tag_set->tags[] ---> rqs [ ][ ][ ][ ][ ][ ] a reverse mapping from tag to request
| /
+--> static_rqs[] /
/ /
___ ___ __/____ ___ /
| | | | | | w/o scheduler /
|___|___|___|___|___| <---------------------------
/\
/ \
_________/ \___________
| request + driver payload |
Quote from Jen's paper Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems
While global sequential re-ordering is still possible across the multiple software
queues, it is only necessary for HDD based devices, where the additional latency
and locking overhead required to achieve total ordering does not hurt IOPS
performance."
"for many users, it is no longer necessary to employ advanced fairness scheduling
as the speed of the devices are often exceeding the ability of even multiple
applications to saturate their performance. If fairness is essential, it is possible to
design a scheduler that exploits the characteristics of SSDs at coarser granularity to
achieve lower performance overhead"
The 3 io schedulers in current blk-mq seems to accord with what jens said.
The available io scheduler for blk-mq
Let's look at the kyber.
kyber, the lightweight io scheduler for fast SSDs
Quote from https://lwn.net/Articles/720675/
BFQ is a complex scheduler that is designed to provide good interactive
response, especially on those slower devices. It has a relatively high
per-operation overhead, which is justified when the I/O operations
themselves are slow and expensive. This complexity may not make sense,
though, in situations where I/O operations are cheap and throughput is
a primary concern. When running a server workload using solid-state
devices, it may be better to run a much simpler scheduler that allows
for request merging and perhaps some simple policies, but which mostly
stays out of the way.
Except for the lightweight, the intention of kyber is to keep low level
latency of prioritized requests.
There are 3 domain there: READ, SYNC_WRITE, and OTHER (async writes, discard)
Note: some request will bypass the io scheduler, such as flush.
How does it work ?
kyber_dispatch_request()
-> kyber_dispatch_cur_domain()
>>>>
rqs = &khd->rqs[khd->cur_domain];
rq = list_first_entry_or_null(rqs, struct request, queuelist);
/*
* If there wasn't already a pending request and we haven't flushed the
* software queues yet, flush the software queues and check again.
*/
if (!rq && !*flushed) {
kyber_flush_busy_ctxs(khd, hctx);
// flush the requests from the ctx software queue to kyber queue.
*flushed = true;
rq = list_first_entry_or_null(rqs, struct request, queuelist);
}
if (rq) {
nr = kyber_get_domain_token(kqd, khd, hctx);
-> __sbitmap_queue_get()
if (nr >= 0) {
khd->batching++;
rq_set_domain_token(rq, nr);
list_del_init(&rq->queuelist);
return rq;
}
}
>>>>
Every domain has its own queue depth, look at the default ones:
static const unsigned int kyber_depth[] = {
[KYBER_READ] = 256,
[KYBER_SYNC_WRITE] = 128,
[KYBER_OTHER] = 64,
};
It is similar with the blk-mq tags, but it is called token here.
The queue size of every domain will be resized based on the req latency.
kyber exploit the blk_stat mechanism to collect latency statistics and Adjust
the domain queue size in the blk_stat timer fn.
static int kyber_lat_status(struct blk_stat_callback *cb,
unsigned int sched_domain, u64 target)
{
u64 latency;
if (!cb->stat[sched_domain].nr_samples)
return NONE;
latency = cb->stat[sched_domain].mean;
if (latency >= 2 * target)
return AWFUL;
else if (latency > target)
return BAD;
else if (latency <= target / 2)
return GREAT;
else /* (latency <= target) */
return GOOD;
}
static void kyber_stat_timer_fn(struct blk_stat_callback *cb)
{
struct kyber_queue_data *kqd = cb->data;
int read_status, write_status;
read_status = kyber_lat_status(cb, KYBER_READ, kqd->read_lat_nsec);
write_status = kyber_lat_status(cb, KYBER_SYNC_WRITE, kqd->write_lat_nsec);
kyber_adjust_rw_depth(kqd, KYBER_READ, read_status, write_status);
kyber_adjust_rw_depth(kqd, KYBER_SYNC_WRITE, write_status, read_status);
kyber_adjust_other_depth(kqd, read_status, write_status,
cb->stat[KYBER_OTHER].nr_samples != 0);
/*
* Continue monitoring latencies if we aren't hitting the targets or
* we're still throttling other requests.
*/
if (!blk_stat_is_active(kqd->cb) &&
((IS_BAD(read_status) || IS_BAD(write_status) ||
kqd->domain_tokens[KYBER_OTHER].sb.depth < kyber_depth[KYBER_OTHER])))
blk_stat_activate_msecs(kqd->cb, 100);
}
There is no insert_requests callbacks in kyber, so the merge/sort will be done
by the ctx software queue.
Quiescing and freezing a blk-mq queue is different.
Let's check the source code.
blk_mq_quiesce_queue()
>>>>
blk_mq_quiesce_queue_nowait(q);
>>>>
spin_lock_irqsave(q->queue_lock, flags);
queue_flag_set(QUEUE_FLAG_QUIESCED, q);
spin_unlock_irqrestore(q->queue_lock, flags);
>>>>
queue_for_each_hw_ctx(q, hctx, i) {
if (hctx->flags & BLK_MQ_F_BLOCKING)
synchronize_srcu(hctx->queue_rq_srcu);
else
rcu = true;
}
if (rcu)
synchronize_rcu();
>>>>
__blk_mq_run_hw_queue()
>>>>
if (!(hctx->flags & BLK_MQ_F_BLOCKING)) {
rcu_read_lock();
run_queue = blk_mq_sched_dispatch_requests(hctx);
rcu_read_unlock();
} else {
might_sleep();
srcu_idx = srcu_read_lock(hctx->queue_rq_srcu);
run_queue = blk_mq_sched_dispatch_requests(hctx);
srcu_read_unlock(hctx->queue_rq_srcu, srcu_idx);
}
>>>>
Look at the rcu/srcu lock in __blk_mq_run_hw_queue().
static void __blk_mq_run_hw_queue(struct blk_mq_hw_ctx *hctx)
{
int srcu_idx;
/*
* We should be running this queue from one of the CPUs that
* are mapped to it.
*/
WARN_ON(!cpumask_test_cpu(raw_smp_processor_id(), hctx->cpumask) &&
cpu_online(hctx->next_cpu));
/*
* We can't run the queue inline with ints disabled. Ensure that
* we catch bad users of this early.
*/
WARN_ON_ONCE(in_interrupt());
if (!(hctx->flags & BLK_MQ_F_BLOCKING)) {
rcu_read_lock();
blk_mq_sched_dispatch_requests(hctx);
rcu_read_unlock();
} else {
might_sleep();
srcu_idx = srcu_read_lock(hctx->queue_rq_srcu);
blk_mq_sched_dispatch_requests(hctx);
srcu_read_unlock(hctx->queue_rq_srcu, srcu_idx);
}
}
So when the blk_mq_quiesce_queue() returns, we could ensure that all the __blk_mq_run_hw_queue
has returned and the following blk_mq_sched_dispatch_requests() will see the QUEUE_FLAG_QUIESCED.
Consequently, there will be no requests issued after blk_mq_quiesce_queue().
When the queue is quiesced, the requests will not be handled, but could be allocated and queued.
blk_mq_freeze_queue() will increase the q->mq_freeze_depth and wait until the
q->q_usage_counter.
This two counter play very important role in blk-mq path.
q_usage_counter covers nearly all the path of blk-mq, more importantly, every
request will hold one reference of q_usage_counter until it is freed.
blk_mq_make_request()
-> blk_mq_get_request()
-> blk_queue_enter_live()
// add 1 here
blk_mq_free_request()
-> blk_queue_exit()
Other other hand, the mq_freeze_depth will gate blk-mq path.
generic_make_request()
-> blk_queue_enter()
>>>>
ret = wait_event_interruptible(q->mq_freeze_wq,
!atomic_read(&q->mq_freeze_depth) ||
blk_queue_dying(q));
>>>>
Therfore, we know that when the blk_mq_free_queue() returns, all the requests
has been drained and no new request will enter the io path.
An issue about the queue quiesced flag.
https://lkml.org/lkml/2017/10/3/548
Look at the source code
blk_mq_alloc_tag_set()
-> blk_mq_update_queue_map()
-> blk_mq_map_queues()
>>>>
for_each_possible_cpu(cpu) { use possible_cpu here
/*
* First do sequential mapping between CPUs and queues.
* In case we still have CPUs to map, and we have some number of
* threads per cores then map sibling threads to the same queue for
* performace optimizations.
*/
if (cpu < nr_queues) {
map[cpu] = cpu_to_queue_index(nr_queues, cpu);
} else {
first_sibling = get_first_sibling(cpu);
if (first_sibling == cpu)
map[cpu] = cpu_to_queue_index(nr_queues, cpu);
else
map[cpu] = map[first_sibling];
}
>>>>
Do the mapping from cpu to hctx queue.
blk_mq_init_allocated_queue()
-> q->mq_map = set->mq_map
-> blk_mq_map_swqueue()
>>>>
for_each_present_cpu(i) {
hctx_idx = q->mq_map[i]; // the hctx to which this cpu are mapped
>>>>
ctx = per_cpu_ptr(q->queue_ctx, i);
hctx = blk_mq_map_queue(q, i);
cpumask_set_cpu(i, hctx->cpumask); // mark this cpu on the hctx
ctx->index_hw = hctx->nr_ctx;
hctx->ctxs[hctx->nr_ctx++] = ctx;
}
>>>>
Gather the cpus that mapped to one hctx queue to the hctx queue
Including:
this index_hw is very important, the hw queue will know there is pending request on the ctx queue through it.
__blk_mq_insert_request()
-> __blk_mq_insert_request()
-> blk_mq_hctx_mark_pending()
-> sbitmap_set_bit(&hctx->ctx_map, ctx->index_hw);
blk_mq_flush_busy_ctxs()
-> sbitmap_for_each_set(&hctx->ctx_map, flush_busy_ctx, &data);
Currently, blk-mq only do the mapping with present cpu. This is due to a commit:
4b855ad (blk-mq: Create hctx for each present CPU)
It used to do the mapping with online cpu. Every time with cpu hotplug, blk-mq
has to adjust the mapping. During this process, it will try to freeze the queue
and wait all the reqs to be completed(every req holds a q->q_usage_counter).
However, this could introduce some deadlock scenario, for example,
the following commit:
302ad8c (nvme: Complete all stuck requests)
When we suspend the nvme device, the reqs that has been started will be
cancelled and requeued, but the q->q_usage_counter will still be held. Because
the queue has been quiesced, these rqs cannot be handled and q->q_usage_counter
cannot be released, the cpu hotplug in blk-mq process cannot make progress forward and
stucks there.
Therefore, the 4b855ad (blk-mq: Create hctx for each present CPU) was introduced.
But this introduced some other regression, look at the following mail thread.
https://lkml.org/lkml/2017/11/21/583
As the Christian said
I am not doing a hot unplug and the replug, I use KVM and add a previously
not available CPU.
The cpu_present_mask could be modified at this moment, the WARN_ON in __blk_mq_run_hw_queue
will be triggered.
WARN_ON(!cpumask_test_cpu(raw_smp_processor_id(), hctx->cpumask) &&
cpu_online(hctx->next_cpu));
On the other hand, the new present cpu ctx->index_hw is zero, when there is pending reqs on its software queue,
the hctx will goto ctx of cpu0 to get rqs, the reqs on the new present cpu cannot be handled forever.
Will be a hctx executed on other cpu where it is not mapped ?
For example, a nvme card on a 8-core PC will create 8 sq-cq pairs as well as 8
blk_mq_hw_ctxs. Let's look at the mapping between hctx and cpu first.
blk_mq_alloc_tag_set()
-> blk_mq_update_queue_map()
-> nvme_pci_map_queues()
-> blk_mq_pci_map_queues()
>>>>
for (queue = 0; queue < set->nr_hw_queues; queue++) {
mask = pci_irq_get_affinity(pdev, queue);
if (!mask)
goto fallback;
for_each_cpu(cpu, mask)
set->mq_map[cpu] = queue;
}
return 0;
>>>>
Then in
blk_mq_init_allocated_queue()
-> blk_mq_map_swqueue()
>>>>
for_each_present_cpu(i) {
hctx_idx = q->mq_map[i];
>>>>
ctx = per_cpu_ptr(q->queue_ctx, i);
hctx = blk_mq_map_queue(q, i);
cpumask_set_cpu(i, hctx->cpumask);
ctx->index_hw = hctx->nr_ctx;
hctx->ctxs[hctx->nr_ctx++] = ctx;
}
>>>>
nvme_alloc_ns()
-> device_add_disk()
-> blk_register_queue()
-> __blk_mq_register_dev()
-> echo hctx blk_mq_register_hctx()
>>>>
ret = kobject_add(&hctx->kobj, &q->mq_kobj, "%u", hctx->queue_num);
if (ret)
return ret;
hctx_for_each_ctx(hctx, ctx, i) {
ret = kobject_add(&ctx->kobj, &hctx->kobj, "cpu%u", ctx->cpu);
if (ret)
break;
}
>>>>
We could get mapping between hctx and cpu througth sysfs.
will@will-ThinkCentre-M910s:/sys/block/nvme0n1/mq$ tree
.
├── 0
│ ├── cpu0
│ ├── cpu_list
│ ├── nr_reserved_tags
│ └── nr_tags
├── 1
│ ├── cpu1
│ ├── cpu_list
│ ├── nr_reserved_tags
│ └── nr_tags
├── 2
│ ├── cpu2
│ ├── cpu_list
│ ├── nr_reserved_tags
│ └── nr_tags
├── 3
│ ├── cpu3
│ ├── cpu_list
│ ├── nr_reserved_tags
│ └── nr_tags
├── 4
│ ├── cpu4
│ ├── cpu_list
│ ├── nr_reserved_tags
│ └── nr_tags
├── 5
│ ├── cpu5
│ ├── cpu_list
│ ├── nr_reserved_tags
│ └── nr_tags
├── 6
│ ├── cpu6
│ ├── cpu_list
│ ├── nr_reserved_tags
│ └── nr_tags
└── 7
├── cpu7
├── cpu_list
├── nr_reserved_tags
└── nr_tags
16 directories, 24 files
Now, we have know that every hctx has been mapped to a specific cpu.
Return to our question, will a hctx executed on the other cpu to where
it is not mapped ?
There are two paths that executes the hctx, sync and async.
Let's look at one of the sync path.
blk_mq_make_request()
>>>>
rq = blk_mq_get_request(q, bio, bio->bi_opf, &data);
// blk_mq_get_ctx() will invoke get_cpu() to disable the preempt
>>>>
} else if (q->nr_hw_queues > 1 && is_sync) {
blk_mq_put_ctx(data.ctx); // preempt enabled again.
blk_mq_bio_to_request(rq, bio);
// There seem to be a gap here with preempt enabled and the
// current task maybe migrated to other cpu.
blk_mq_try_issue_directly(data.hctx, rq, &cookie);
}
>>>> Let's look into the blk_mq_try_issue_directly()
>>>>
if (!(hctx->flags & BLK_MQ_F_BLOCKING)) {
// nvme doesn't have this BLK_MQ_F_BLOCKING
rcu_read_lock(); // preempt disable here
__blk_mq_try_issue_directly(hctx, rq, cookie, false);
rcu_read_unlock();
}
>>>>
Another sync path.
blk_mq_requeue_work()
-> blk_mq_run_hw_queues() // async = false
-> echo hctx run blk_mq_run_hw_queue()
blk_freeze_queue_start()
-> blk_mq_run_hw_queues() // async = false
The two paths above must will execute the hctxs on the the cpu where they are not mapped.
For the async path, scenario seems different.
__blk_mq_delay_run_hw_queue() will invoke blk_mq_hctx_next_cpu() to decide
on which cpu queue the hctx->run_work, then the blk_mq_run_work_fn() will
be executed on the kworker that has been pinned on a specific cpu.
The driver tags could be shared between different request_queues. We could think
fo the following scenario.
SCSI HBA ------> SCSI TARGET +------> LU 0
|
+------> LU 1
|
+------> LU 2
|
+------> LU 3
The count of LU could be very big in SAN case.
How does the blk-mq handle the fairness between different request_queues on the
same tag_set ?
First, we to tell the request_queue and blk tag_set that the tag_set is shared.
blk_mq_init_allocated_queue()
-> blk_mq_add_queue_tag_set()
static void blk_mq_add_queue_tag_set(struct blk_mq_tag_set *set,
struct request_queue *q)
{
q->tag_set = set;
mutex_lock(&set->tag_list_lock);
/*
* Check to see if we're transitioning to shared (from 1 to 2 queues).
*/
if (!list_empty(&set->tag_list) &&
!(set->flags & BLK_MQ_F_TAG_SHARED)) {
set->flags |= BLK_MQ_F_TAG_SHARED;
/* update existing queue */
blk_mq_update_tag_set_depth(set, true);
/*
Actually, only the first request_queue on this tag_set will be set here.
The blk-mq will be frozen and the hctxs associated with request_queue
will be set BLK_MQ_F_TAG_SHARED.
*/
}
if (set->flags & BLK_MQ_F_TAG_SHARED)
queue_set_hctx_shared(q, true); // Set the BLK_MQ_F_TAG_SHARED
list_add_tail_rcu(&q->tag_set_list, &set->tag_list);
mutex_unlock(&set->tag_list_lock);
}
In addition, the meaning of sharing tag_set is to share the driver tags. Look at
the following code:
blk_mq_init_allocated_queue()
-> blk_mq_add_queue_tag_set()
-> blk_mq_map_swqueue()
>>>>
queue_for_each_hw_ctx(q, hctx, i) {
>>>>
hctx->tags = set->tags[i];
WARN_ON(!hctx->tags);
>>>>
}
>>>>
Then all the things will occur around this BLK_MQ_F_TAG_SHARED.
driver tags allocation
blk_mq_get_request()
-> blk_mq_rq_ctx_init()
Or
blk_mq_get_driver_tag()
>>>>
if (blk_mq_tag_busy(data.hctx)) {
rq->rq_flags |= RQF_MQ_INFLIGHT;
atomic_inc(&data.hctx->nr_active);
}
>>>>
blk_mq_tag_busy() will only return true when BLK_MQ_F_TAG_SHARED is set.
In __blk_mq_tag_busy(), the BLK_MQ_S_TAG_ACTIVE will be set and
hctx->tags->active_queues will be increased.
In addition, the hctx->nr_active will also be increased.
The hctx->tags->nr_actives is the count of request_queues that use the driver tag.
The hctx->nr_active is the count of driver tags used by the hctx itself
Where will be these two values used ?
blk_mq_get_request()/blk_mq_get_driver_tag()
-> blk_mq_get_tag()
-> __blk_mq_get_tag() // if !BLK_MQ_REQ_INTERNAL
-> hctx_may_queue()
static inline bool hctx_may_queue(struct blk_mq_hw_ctx *hctx,
struct sbitmap_queue *bt)
{
unsigned int depth, users;
if (!hctx || !(hctx->flags & BLK_MQ_F_TAG_SHARED))
return true;
if (!test_bit(BLK_MQ_S_TAG_ACTIVE, &hctx->state))
return true;
/*
* Don't try dividing an ant
*/
if (bt->sb.depth == 1)
return true;
users = atomic_read(&hctx->tags->active_queues);
if (!users)
return true;
/*
* Allow at least some tags
*/
depth = max((bt->sb.depth + users - 1) / users, 4U);
return atomic_read(&hctx->nr_active) < depth;
}
It is easy to understand the source code above. It just averages the tag depth to
among the active request_queues to ensure fairness. But it look like not fair
when a high workload on LU0 and a relatively low workload on LU1. Another sad
thing is the active_queues will only be decreased when the queue is timed out or
exits( Look at the blk_mq_tag_idle() ). This indicates that the tags will be shared
between the LUs no matter whether there is workload on the LUs.
driver tag release
__blk_mq_put_driver_tag()/blk_mq_free_request()
>>>>
if (rq->rq_flags & RQF_MQ_INFLIGHT) {
rq->rq_flags &= ~RQF_MQ_INFLIGHT;
atomic_dec(&hctx->nr_active);
}
>>>>
hctx->nr_active will be decreased here.
restart hctxs
If we submit a req to blk-mq, when will the reqs not be issued ?
Regarding the a.
blk_mq_mark_tag_wait() will be invoked by blk_mq_dispatch_rq_list().
(A commit that optimize this path f906a6a blk-mq: improve tag waiting setup for non-shared tags)
For the non-shared-tags case, the BLK_MQ_S_SCHED_RESTART flag will be enough.
But for the shared-tags case, it uses the sbq_wake_up().
Regarding the b.
Look at the comment of blk_mq_sched_restart()
Called after a driver tag has been freed to check whether a hctx needs to
be restarted. Restarts @hctx if its tag set is not shared. Restarts hardware
queues in a round-robin fashion if the tag set of @hctx is shared with other
hardware queues.
Look at the round-robin part:
>>>>
list_for_each_entry_rcu_rr(q, queue, &set->tag_list,
tag_set_list) {
queue_for_each_hw_ctx(q, hctx2, i)
if (hctx2->tags == tags &&
blk_mq_sched_restart_hctx(hctx2))
goto done;
}
>>>>
blk_mq_sched_restart_hctx() will run the hctx in async fashion if has work
pending on it.
Regarding the blk-mq polling, please refer to Block-layer I/O polling
blk_mq_poll()
-> rq = blk_mq_tag_to_rq() //hctx->tags/hctx->sched_tags based on the cookie
-> __blk_mq_poll()
>>>>
while (!need_resched()) {
int ret;
hctx->poll_invoked++;
ret = q->mq_ops->poll(hctx, rq->tag);
if (ret > 0) {
hctx->poll_success++;
set_current_state(TASK_RUNNING);
return true;
}
>>>>
if (ret < 0)
break;
cpu_relax();
}
>>>>
static int __nvme_poll(struct nvme_queue *nvmeq, unsigned int tag)
{
struct nvme_completion cqe;
int found = 0, consumed = 0;
if (!nvme_cqe_valid(nvmeq, nvmeq->cq_head, nvmeq->cq_phase))
return 0;
//First check whether there is valid cqe, if no, return.
//This procedure is interrupt-enabled, before __nvme_poll() get the valid
//cqe, the interrupt has come and process the cqe. So nvme_poll() will not
//get any cqe here, but how does it get out of the loop of __blk_mq_poll() ?
spin_lock_irq(&nvmeq->q_lock);
while (nvme_read_cqe(nvmeq, &cqe)) {
nvme_handle_cqe(nvmeq, &cqe);
consumed++;
if (tag == cqe.command_id) {
found = 1;
break;
}
}
if (consumed)
nvme_ring_cq_doorbell(nvmeq);
spin_unlock_irq(&nvmeq->q_lock);
return found;
In fact, it cannot disable the irq there, because the context may have been migrated to other cpu
}
The answer is task state.
__blkdev_direct_IO_simple()
>>>>
qc = submit_bio(&bio);
for (;;) {
set_current_state(TASK_UNINTERRUPTIBLE);
if (!READ_ONCE(bio.bi_private))
break;
if (!(iocb->ki_flags & IOCB_HIPRI) ||
!blk_mq_poll(bdev_get_queue(bdev), qc))
io_schedule();
}
>>>>
The task state is set to TASK_UNINTERRUPTIBLE
The blk completion path will try to wake up this
process in bi_end_io callback, blkdev_bio_end_io_simple()
try_to_wake_up()
-> ttwu_queue()
-> ttwu_do_activate()
-> ttwu_do_wakeup()
-> p->state = TASK_RUNNING
in loop of __blk_mq_poll(), it will check the task state.
>>>>
while (!need_resched()) {
int ret;
hctx->poll_invoked++;
ret = q->mq_ops->poll(hctx, rq->tag);
>>>>
if (current->state == TASK_RUNNING)
return true;
if (ret < 0)
break;
cpu_relax();
}
>>>>
if the task state is set to TASK_RUNNING, it returns true.
The following is test result w/ or w/o blk-mq polling.
w/o blk-mq polling
read : io=131072KB, bw=79007KB/s, iops=19751, runt= 1659msec
clat (usec): min=27, max=253, avg=49.46, stdev=33.61
w/ blk-mq polling
read : io=131072KB, bw=97019KB/s, iops=24254, runt= 1351msec
clat (usec): min=19, max=302, avg=40.90, stdev=34.31
The difference of average completion latency is 9us, about the time of two scheduling.